
GAN已死?GAN万岁!布朗康奈尔新作爆火,一夜碾压扩散模型
内容转载自:新智元
GAN已死?
不,GAN又回来了!


此前曾掀起AI圈巨大风暴的GAN,后来却逐渐沉寂了,甚至有人发出了「GAN已死」的论调。

2022年,「GAN已经过时、被扩散模型取代」的论调激起热议
原因有很多,比如人们普遍觉得GAN很难训练,文献中的GAN架构也充斥着经验技巧。
但就在刚刚,布朗大学和康奈尔的研究者在这篇论文中,要彻底为GAN正名!

论文地址:https://arxiv.org/abs/2501.05441
论文中,作者提出了一种突破性的新型GAN架构——R3GAN(Re-GAN),其最大核心亮点在于,引入了全新的正则化相对性损失函数。
它不仅在理论上证明了局部收敛性,更在实践中显著提升了模型训练的稳定性。
这一突破,使得模型能够摒弃传统GAN中必须依赖的各种技巧,转而采用了更加现代化的深度学习架构。
结果证明,一个不使用任何技巧的极简GAN,能够以一半的模型参数,以及单步生成的方式达到与EDM(扩散模型)相当的性能。

就看这个R3GAN的出图质量是多么地稳定!

围观网友们表示,这绝对是改变游戏规则的一项研究——如果能正确地训练GAN,那简直就是一场噩梦。

在智能体非常爆火的当下,GAN显得前途无量。
因为GAN非常适合需要速度的专门任务,而Transformer则适用于其他所有任务。智能体就可以使用GAN,来加速部分流程,或做出时间关键的决策。
一、扩散模型风生水起,GAN却陷困境
还记得2014年,当Goodfellow等人首次提出GAN时,整个AI界都为之震动。
一个能够通过单词前向传播生成高质量的模型,简直就是一场革命。

论文地址:https://arxiv.org/pdf/1406.2661
然而,随之而来的困扰也接踵而至——训练不稳定性,成为了挥之不去的阴影。
对于研究人员来说,他们担忧的是害怕模型训练随时会「暴走」,或者生成的图像千篇一律,失去了应有的多样性。
尽管这些年,GAN的目标函数不断改进,但在具体实践中,这些函数的问题是始终如影随形,一直以来对GAN研究产生了持久的负面影响。

随后,2019年,著名的StyleGAN架构诞生了。它就像是一个「补丁大师」,为了提高稳定性,使用了梯度惩罚的非饱和损失;同时又为了增加样本多样性,又不得不采用小批量标准差的技巧。

论文地址:https://arxiv.org/pdf/1812.04948
这些看似矛盾的做法,实际上反映了GAN架构本身的局限性。
更有趣的是,如果去除这些技巧,StyleGAN的骨干网络竟和2015年的DCGAN惊人地相似!
这就不禁让人思考:为什么其他生成模型,比如扩散模型,都能得到快速改进,而GAN却似乎停滞不前?
在扩散模型中,多头自注意力等等现代计算机视觉技术,以及预激活ResNet、U-Net和视觉Transformer(ViT)等骨干网络已成为常态。
考虑到这些过时的骨干网络,人们普遍认为GAN在FID等定量指标方面无法扩展,也就不足为奇了。
好消息是,布朗大学和康奈尔大学的研究人员在这个领域取得了重大的突破。他们提出了一个创新性的解决方案,包含两个关键要素:
1)新型目标函数
将相对配对GAN损失(RpGAN)与零中心梯度惩罚相结合,提高了稳定性。他们在数据上证明了,带梯度惩罚的RpGAN,享有与正则化经典GAN相同的局部收敛性。
2)现代化改造
摒弃StyleGAN反锁技巧,转而采用简洁而高效的现代架构设计。结果发现,适当的ResNet设计、初始化和重采样,同时加上分组卷积和无归一化,就能达到甚至超越StyleGAN的性能。
总的来说,新论文首先从数学上论证了通过改进的正则化损失,让GAN的训练不必那么棘手。
然后,在实验中开发了一个简单的GAN基准,在不使用任何技巧的情况下,在FFHQ、ImageNet、CIFAR和Stacked MNIST数据集上,其FID表现优于StyleGAN、其他最先进的GAN和扩散模型。
那么,研究人员具体是如何做到的呢?
二、RpGAN+R_1+R_2稳定性和多样性
在定义GAN的目标函数时,研究人员面临这两个挑战:稳定性和多样性。
先前的研究中,有的专攻稳定性问题,而有的则处理处理模式崩塌问题。
为了在这两个方面都取得进展,团队将一个稳定的方法与一个基于理论的简单正则化器相结合。
1. 传统GAN
传统GAN是在判别器D_ψ和生成器G_θ之间的极小极大博弈中形成的。给定真实数据x ∼ p_D和G_θ生产的虚假数据x ∼ p_θ,GAN最一般的形式可以表示为:
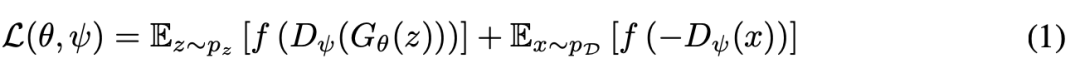
其中G试图最小化L,而D试图最大化G,f的选择是灵活的。特别地,当
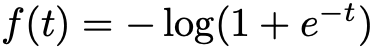
时,就得到了Goodfellow等人提出的经典GAN。
实践已经证明,当p_θ可以直接优化时,该方程具有凸性质。然而,在实际实现中,经验GAN损失通常会将虚假样本推到D设定的决策边界之外,而不是直接更新密度函数 p_θ。
这种偏差导致了一个显著更具挑战性的问题,其特征是容易出现两种普遍的失败情况:模式崩塌/丢失和不收敛。
2. 相对f-GAN(Relativistic f-GAN)
这时,研究人员采用了由Jolicoeur Martineau团队提出的一种略有不同的极小极大博弈,称为相对配对GAN(RpGAN),用于解决模式丢失问题。
一般的RpGAN定义如下:
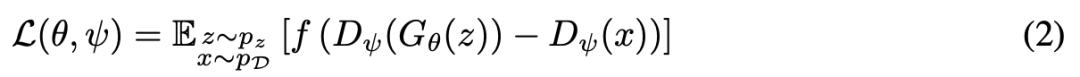
虽然方程2(RpGAN)和方程1(传统GAN)看起来只有细微差别,但评估这种判别器差异对损失函数L的整体形态有根本性影响。
RpGAN通过耦合真实和虚假数据,引入了一个简单的解决方案,即通过将虚假样本相对于真实样本的真实性来进行评判,这有效地在每个真实样本的邻域中维持了一个决策边界,从而防止了模式丢失。
3. RpGAN的训练动态
尽管RpGAN的景观结果,让研究人员能够解决模式丢失的问题,但RpGAN的训练动态还有待研究。
等式2的最终目标是找到平衡点(θ^∗, ψ^∗),使得p_θ^∗ = p_D且Dψ^∗在p_D上处处为常数。
这里,作者提出了两个命题:
命题 I.(非形式化表述):使用梯度下降法时,未正则化的RpGAN并不总是收敛。
命题 II.(非形式化表述):在与Mescheder等人类似的假设条件下,使用R_1或R_2正则化的RpGAN能够实现局部收敛。
对于第一个命题,他们通过分析表明,对于某些类型的p_D,比如接近于delta分布,RpGAN是不会收敛的。因此,为了构建一个表现良好的损失函数,进一步的正则化是必要的。
对于第二个命题,研究的证明类似地分析了在点(θ^∗,ψ^∗)处正则化RpGAN梯度向量场的雅可比(Jacobian)矩阵特征值。他们证明了所有特征值都具有负实部;因此,对于足够小的学习率,正则化RpGAN在(θ^∗,ψ^∗)的邻域内是收敛的。
4. 实际演示
如下图1展示了,使用R_1正则化的传统GAN损失函数,会快速发散。虽然从理论上来说,仅使用R_1正则化的RpGAN足以实现局部收敛,但它也会表现不稳定并且会快速发散。
同时使用R1和R2正则化后,传统GAN和RpGAN的训练都变得稳定。
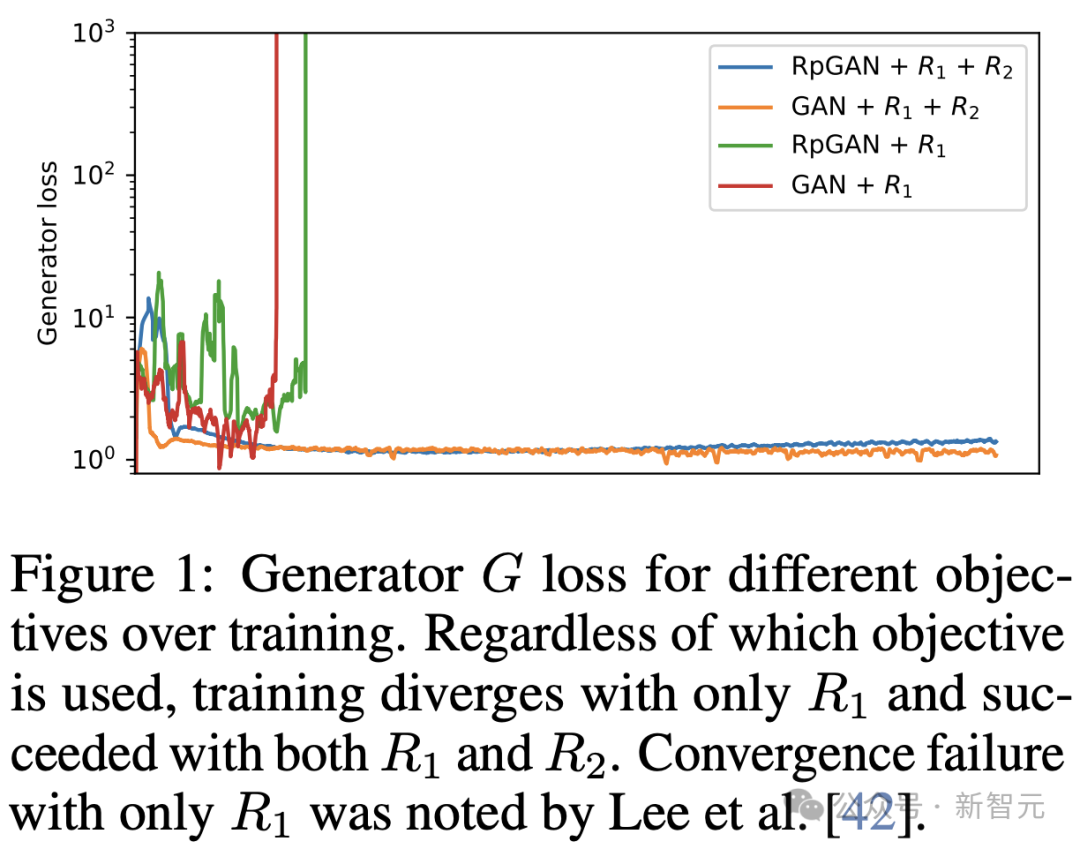
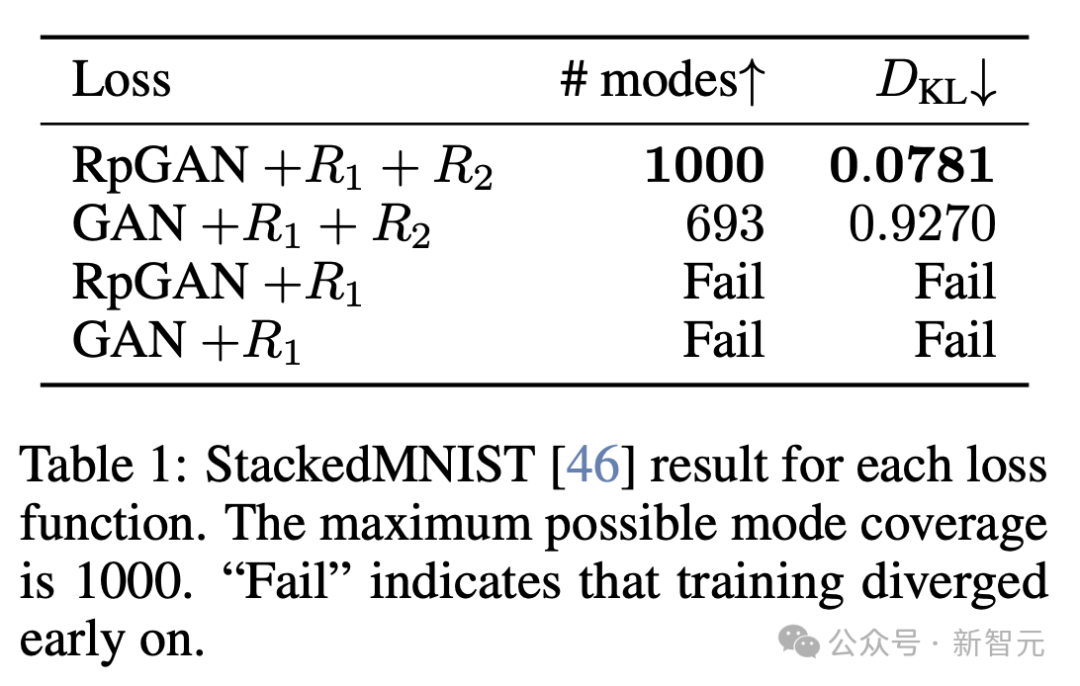
如下表1所示,在稳定的情况下,可以看到传统GAN存在模式丢失问题,而RpGAN则实现了完整的模式覆盖,并将D_KL从0.9270降低到0.0781。
作为对比,StyleGAN使用小批量标准差技巧来减少模式丢失,在StackedMNIST数据集上将模式覆盖从857提高到881,但在D_KL上几乎没有改善。
三、全新基线路线图——R3GAN
精心设计的RpGAN+R_1+R_2损失缓解了GAN的优化问题,使研究者能够以最新的网络骨干进展为基础,构建一个极简的基准模型——R3GAN。
在这项工作中,研究者并不是简单地陈述新方法,而是从StyleGAN2基准模型出发绘制路线图。
该模型包括生成器 (G) 的VGG风格骨干网络、判别器 (D) 的ResNet结构、一系列促进基于风格生成的技术,以及许多弥补弱主干网络缺陷的技巧。
随后,他们移除了StyleGAN2的所有非必要特性,应用了所提出的损失函数,并逐步对网络骨干进行现代化改造。
研究者在FFHQ 256×256数据集上评估了每种配置。
所有配置的网络容量大致保持相同——生成器 (G) 和判别器 (D) 的可训练参数均约为2500万。
每种配置的训练均持续到判别器 (D) 处理了500万张真实图像。除非另有说明,训练的超参数(例如优化器设置、批大小、EMA衰减长度)均沿用自配置A。
研究者针对最终模型调整了训练超参数,并将在第4节中展示其收敛结果。
最小基线(配置B)
研究者移除了所有StyleGAN2的特性,仅保留原始的网络骨干和基础的图像生成能力。
这些特性可分为三类:
- 基于风格的生成:映射网络、风格注入、权重调制/去调制、噪声注入 。
- 图像操作增强:混合正则化、路径长度正则化。
- 技巧:z归一化、小批量标准差、均衡学习率、延迟正则化。
遵循以上做法,研究者将z的维度降低至64。由于移除了均衡学习率,学习率需进一步降低,从原来的2.5×10⁻³降至5×10⁻⁵。
尽管与配置A相比,简化后的基线模型的FID更高,但它仍能生成质量较好的样本,并实现稳定的训练效果。
研究者将其与DCGAN进行比较,主要区别包括:
a) 使用R1正则化的收敛训练目标。
b) 较小的学习率,避免使用带动量的优化器。
c) 在生成器 (G) 和判别器 (D) 中均不使用归一化层。
d) 通过双线性插值进行正确的重采样,而非使用步幅(反卷积)操作。
e) 在G和D中使用leaky ReLU激活函数,G 的输出层中不使用tanh。
f) G使用4×4常量输入,输出跳跃连接,D使用ResNet结构。
1. StyleGAN的实验发现
违反a)、b) 或 c),通常会导致训练失败。前人研究表明,负动量可以改善 GAN的训练动态。
然而,由于负动量的最优设置是一个复杂的超参数,因此研究者选择不使用任何动量,以避免恶化GAN的训练动态。
研究表明,归一化层对生成模型有害。批归一化通常会由于跨多个样本的依赖性而破坏训练,并且与假设每个样本独立处理的R_1、R_2或 RpGAN不兼容。
早期的GAN虽然可能违反a)和c),但仍能成功,这或许是因为它们对方程1提供了一个满秩解。
违反d)或e)虽然不会显著影响训练的稳定性,但会对样本质量产生负面影响。
不正确的反卷积可能导致棋盘伪影,即使使用子像素卷积或精心调整的反卷积也无法解决,除非应用低通滤波器。
插值方法可以避免该问题,为了简化,研究者采用双线性插值。
在激活函数的选择上,研究者选择使用leaky ReLU。
所有后续配置均遵守a)到e)。f)的违反是可以接受的,因为它涉及到 StyleGAN2的网络骨干,在配置D和配置E中已经现代化。
表现良好的损失函数(配置C):研究者采用第2节提出的损失函数,将 FID降低到11.65。他们推测,配置B的网络骨干是性能的限制因素。
通用网络现代化(配置D):研究者首先将1-3-1瓶颈ResNet 架构应用于G和D。该架构是所有现代视觉骨干网络的直接前身。
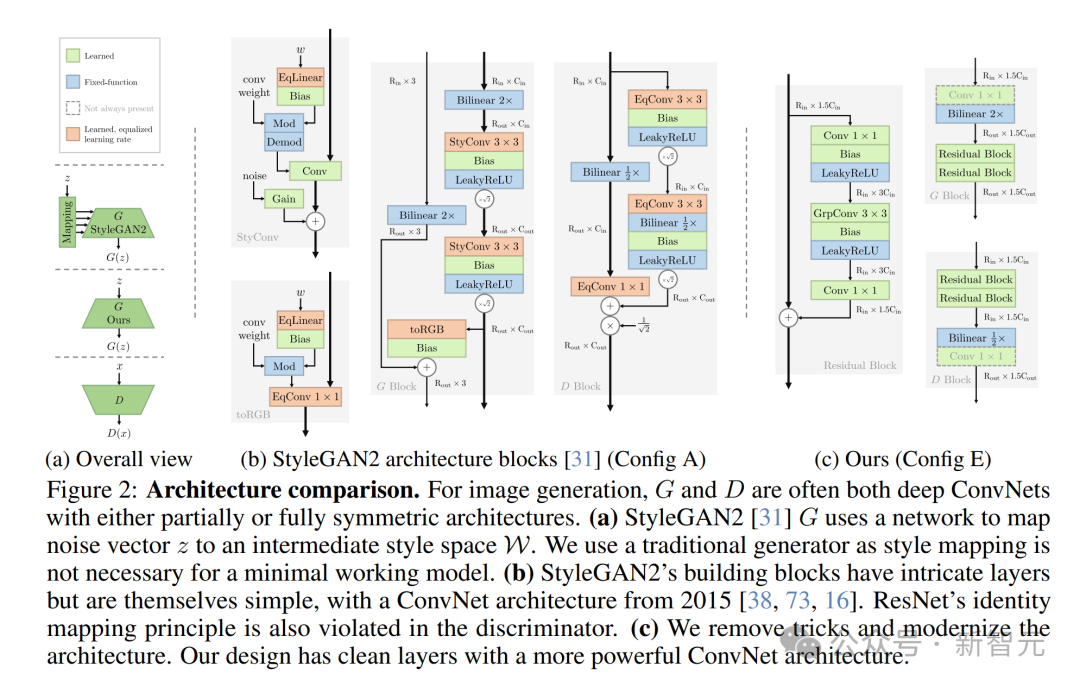
图 2:架构对比。在图像生成中,生成器 (G) 和判别器 (D) 通常都是深度卷积网络 (ConvNets),且架构部分或完全对称。(a) StyleGAN2的生成器 (G) 使用一个网络将噪声向量z映射到中间风格空间W。(b) StyleGAN2的构建模块层次复杂,但其本质仍然简单,采用了2015年的卷积网络架构。(c) 研究者去除了各种技巧并对架构进行了现代化设计,如更干净的层次结构,更强大的卷积网络架构
研究者还结合了从配置B中发现的原则,以及ConvNeXt的各种现代化设计。他们将ConvNeXt的发展路线分为以下几类:
i. 持续有益的改进:
– i.1) 使用深度卷积增加网络宽度,
– i.2) 反转瓶颈结构,
– i.3) 减少激活函数,
– i.4) 独立的重采样层。
ii. 性能提升有限:
– ii.1) 较大卷积核的深度卷积配合更少的通道数,
– ii.2) 用GELU替换ReLU,
– ii.3) 减少归一化层,
– ii.4) 用层归一化替换批归一化。
iii. 与模型无关的改进:
– iii.1) 改进的训练策略,
– iii.2) 阶段比率,
– iii.3) 「patchify」的网络输入层。
研究者计划将i)中的改进应用于他们的模型,特别是针对经典ResNet应用的i.3 和i.4,而i.1和i.2则留待配置E。
2. 神经网络架构细节
基于i.3、i.4以及原则c)、d)和e),研究者将StyleGAN2的骨干替换为现代化的 ResNet。
生成器(G)和判别器(D)的设计完全对称,参数量均为2500万,与配置A相当。
架构设计极简:每个分辨率阶段包含一个转换层和两个残差块。
– 转换层:由双线性重采样和一个可选的1×1卷积层组成,用于改变空间尺寸和特征图通道数。
– 残差块:包括以下五个操作:Conv1×1→Leaky ReLU→Conv3×3→Leaky ReLU→Conv1×1,其中最后的Conv1×1不带偏置项。
对4×4分辨率阶段,转换层在G中被基础层替代,在D中被分类头替代:
– 基础层:类似于StyleGAN,使用4×4可学习特征图,通过线性层调制z。
– 分类头:使用全局4×4深度卷积去除空间维度,然后通过线性层生成D的输出。
四、实验细节
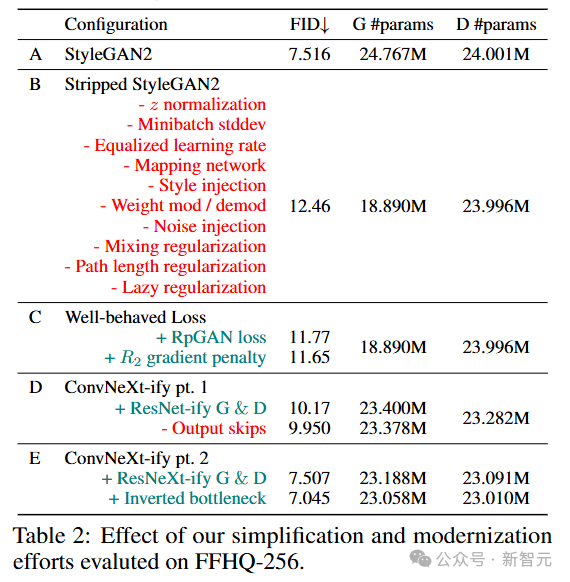
1. FFHQ-256的路线图见解
如表2所示,配置A(原始 StyleGAN2)在FFHQ-256数据集上使用官方实现,达到了7.52的FID。
移除所有技巧的配置B,实现了12.46的FID,性能如预期有所下降。
配置C使用表现良好的损失函数,FID降至11.65,训练稳定性也得到了显著提升,为改进架构提供了可能。
Config D基于经典ResNet和ConvNeXt的研究改进了G和D,FID进一步降至9.95。
在研究者的新架构下,StyleGAN2生成器的输出跳跃连接不再有用,保留它反而会使FID升高至10.17。
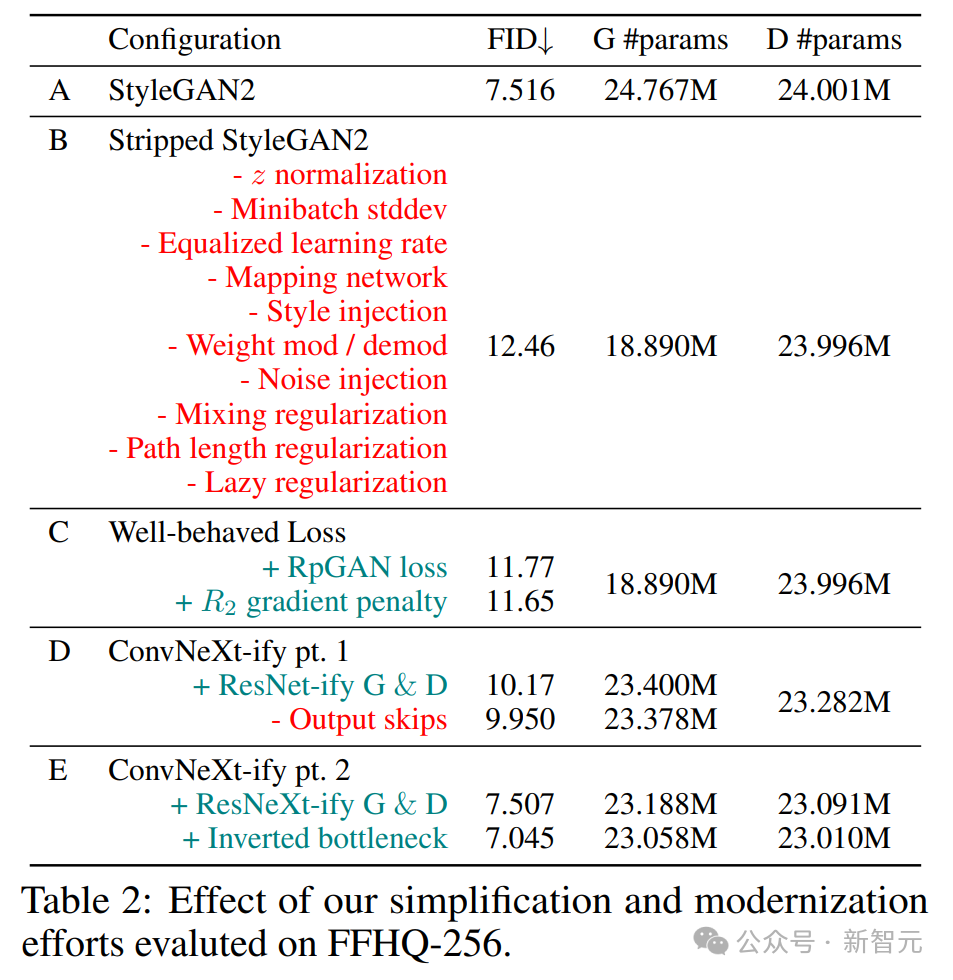
对于Config E,研究者进行了两个实验,分别对 i.1(通过深度卷积增加宽度)和 i.2(反转瓶颈结构)进行消融。
通过反转输入层和瓶颈维度以增强分组卷积的容量,最终模型达到了7.05的 FID,性能超过了StyleGAN2。
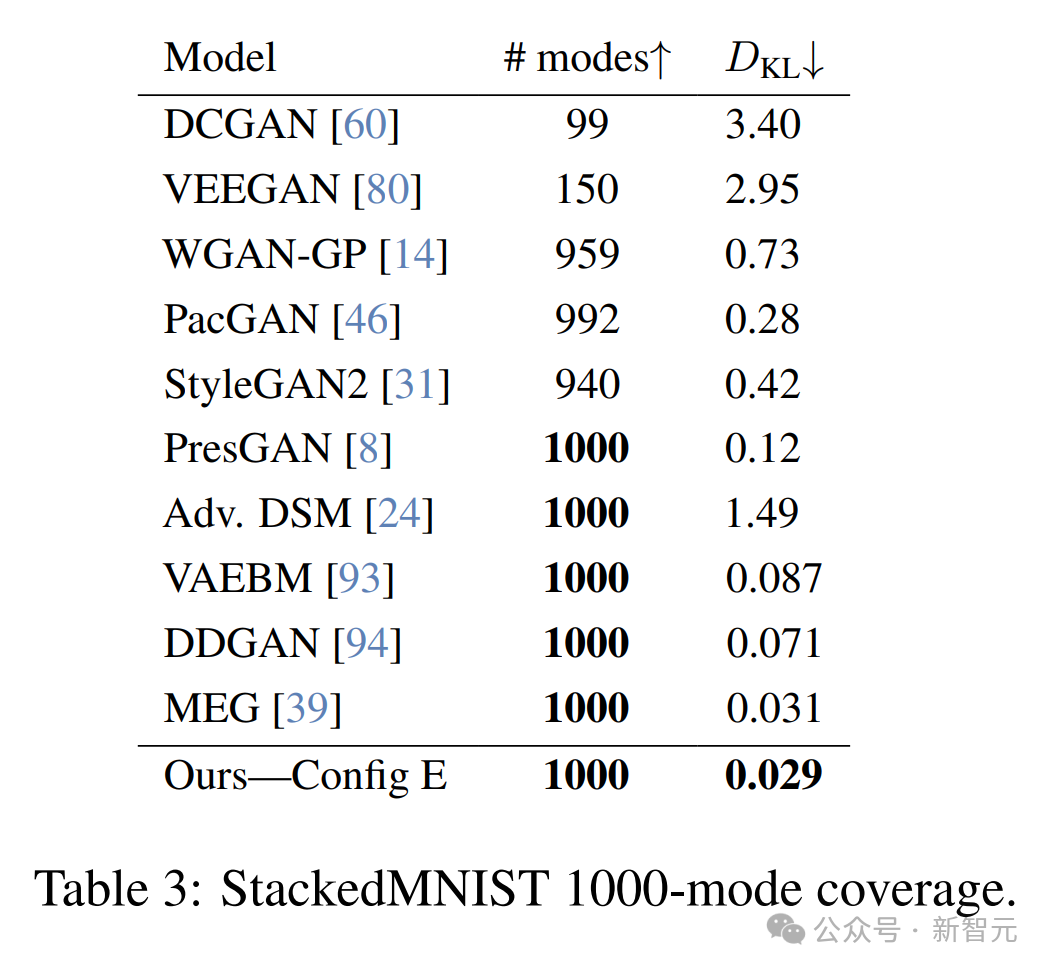
2. 模式恢复实验 – StackedMNIST
研究者在StackedMNIST数据集上重复了早期的1000模态收敛实验,但这次使用了更新后的架构,并与当前最先进的GAN和基于似然的方法进行了比较(见表3和图5)。
基于似然的模型(如扩散模型)的一个优势是能够实现模式覆盖。
研究者发现,大多数GAN都难以捕获所有模态。然而,PresGAN、DDGAN和他们的方法在这方面都取得了成功。

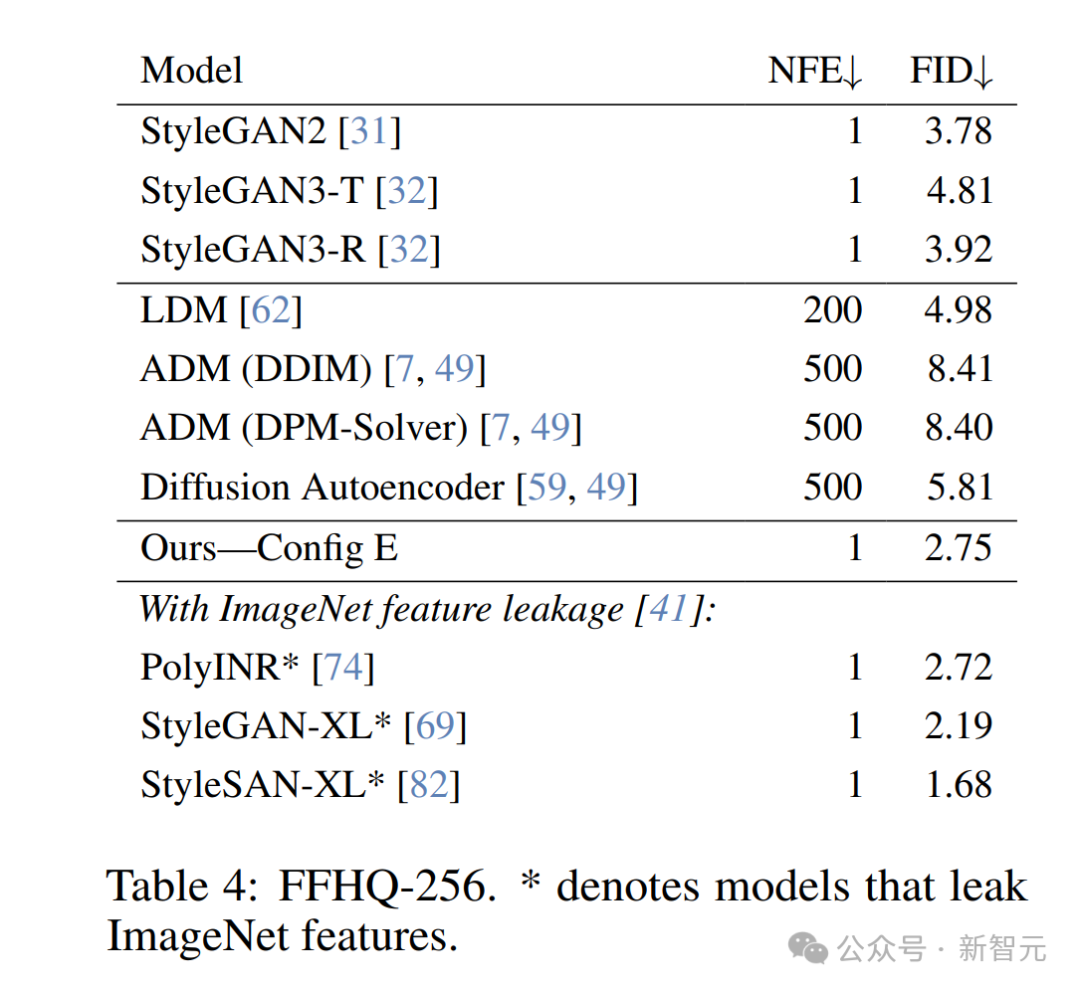
3. FID — FFHQ-256(优化版本)
研究者在FFHQ数据集上,以256×256 分辨率训练Config E模型,直至收敛,并使用了优化的超参数和训练计划(见表4,图4和图6)。
他们的模型在该常见实验设置下,性能优于现有的StyleGAN方法以及四种最新的基于扩散模型的方法。

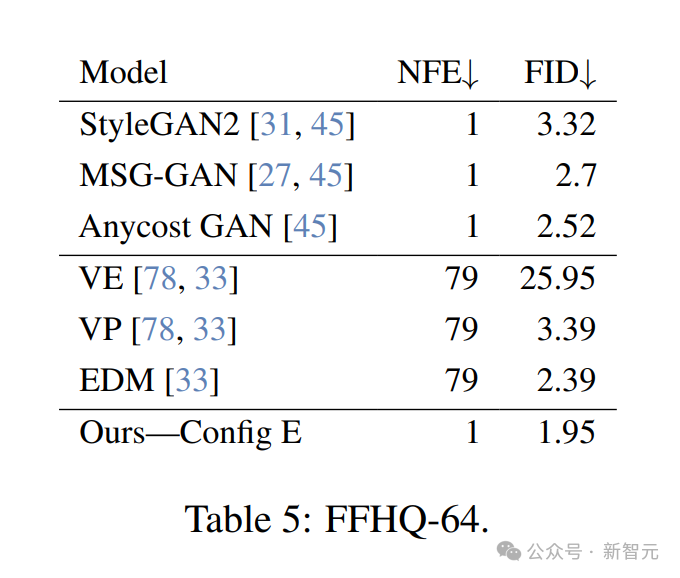
4. FID — FFHQ-64
为了直接与EDM进行比较,研究者在FFHQ数据集上以64×64分辨率评估了模型。
为此,他们移除了256×256模型中两个最高分辨率的阶段,从而使生成器的参数数量不到EDM的一半。
尽管如此,模型在该数据集上的表现仍优于EDM,且仅需一次函数评估。
5. FID — CIFAR-10
研究人员在CIFAR-10数据集上训练Config E模型,直至收敛,并使用了优化的超参数和训练计划(见表6,图8)。
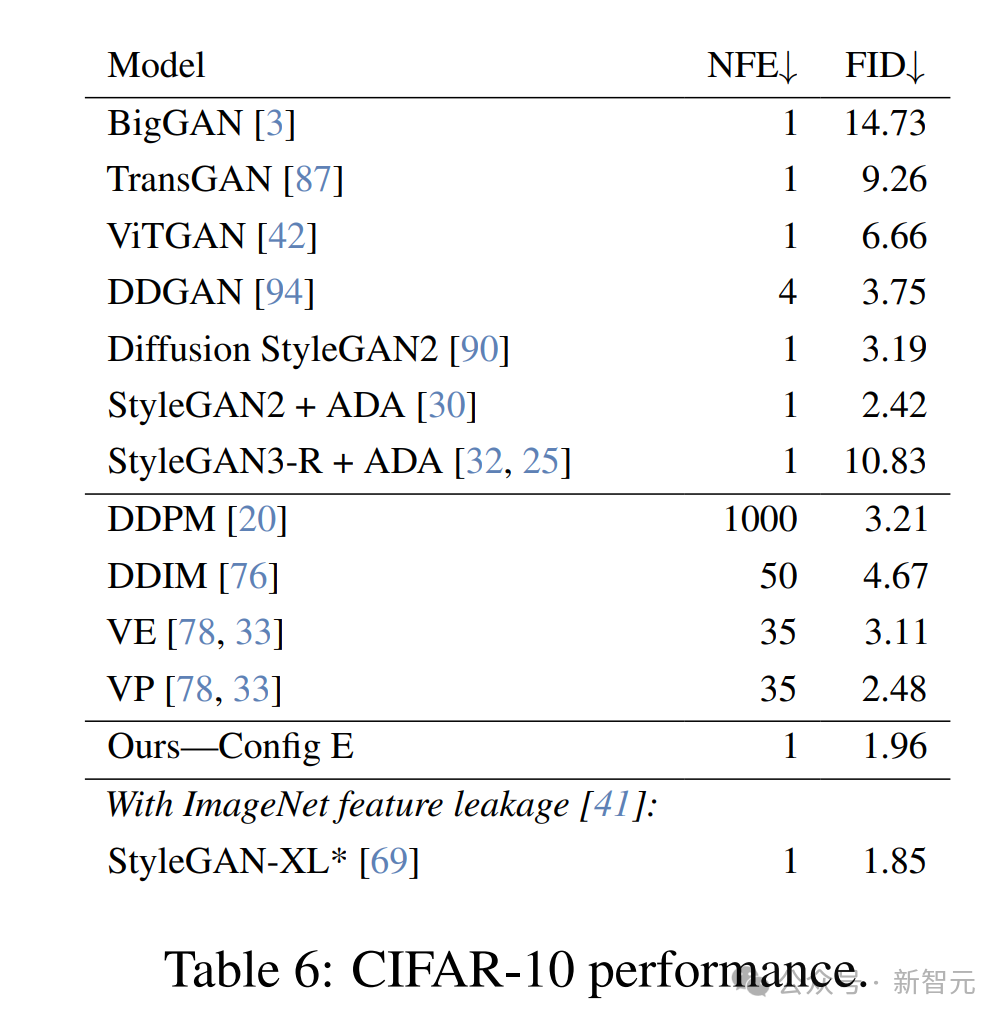

尽管模型容量相对较小,但在FID指标上仍优于许多其他GAN方法。
例如,StyleGAN-XL的生成器参数量为1800万,判别器参数量为1.25亿,而新模型的生成器和判别器总参数量仅为4000万(如下图3所示)。
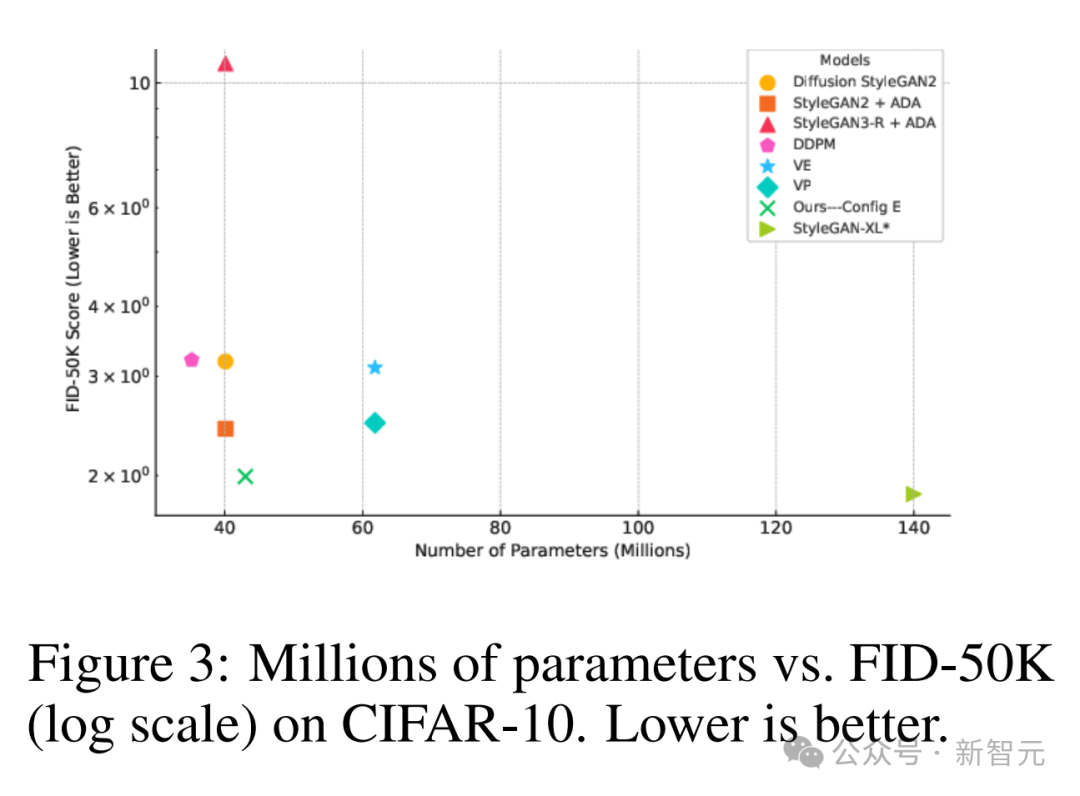
与基于扩散模型的方法(如LDM、ADM)相比,GAN推理显著更高效,因为GAN仅需一次网络函数评估,而扩散模型在没有蒸馏的情况下通常需要数十到数百次评估。
许多当前最先进的GAN都源于Projected GAN,包括StyleGAN-XL和同时期的StyleSAN-XL。这些方法在判别器中使用了一个预训练的ImageNet分类器。
已有研究表明,预训练的ImageNet判别器可能会将ImageNet的特征泄露到模型中,从而导致模型在FID评估中表现更好,因为它依赖于预训练的ImageNet分类器来计算损失。
然而,这并未在感知研究中提升结果。新模型无需任何ImageNet预训练,即可实现较低的FID。
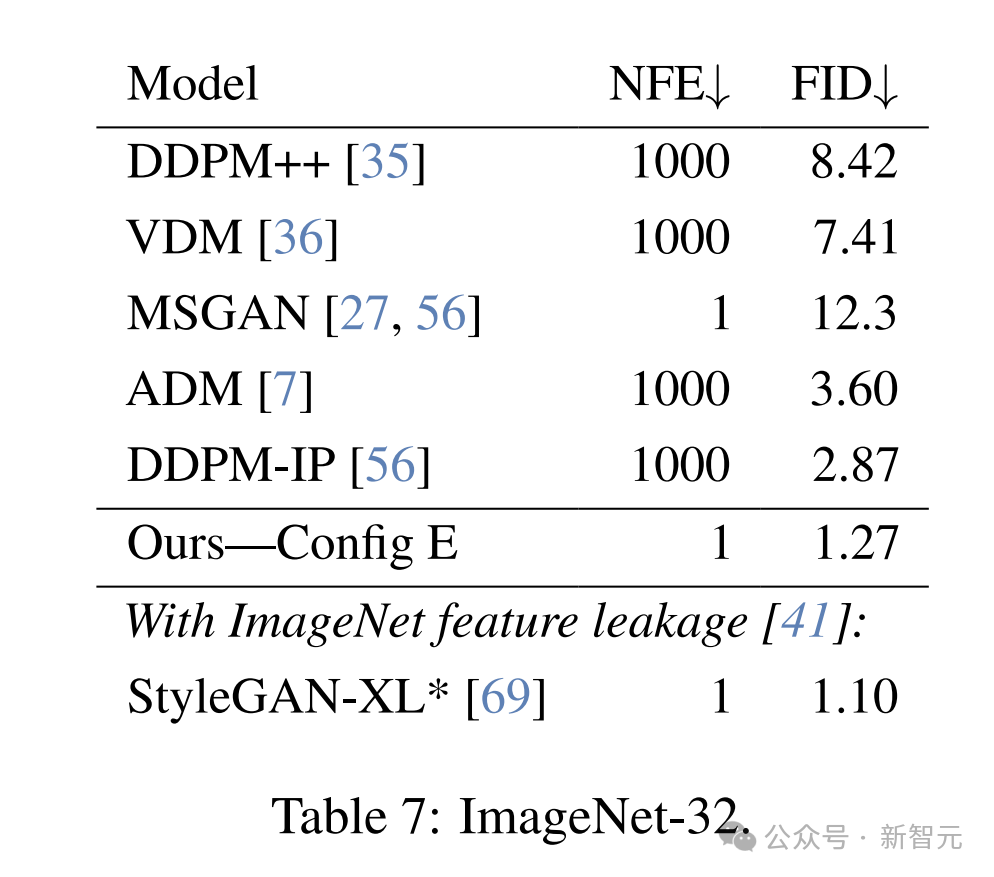
6. FID — ImageNet-32
研究人员在ImageNet-32数据集(条件生成)上训练Config E模型,直至收敛,并使用了优化的超参数和训练计划。
如下表7,对比了新方法与近期的GAN模型和扩散模型。
作者调整了生成器的参数数量,使其与StyleGAN-XL的生成器匹配(84M参数),具体来说,他们将模型显著加宽以达到这一目标。
尽管判别器的参数量比StyleGAN-XL小了60%,且未使用预训练的ImageNet分类器,新方法仍然达到了与其相当的FID。
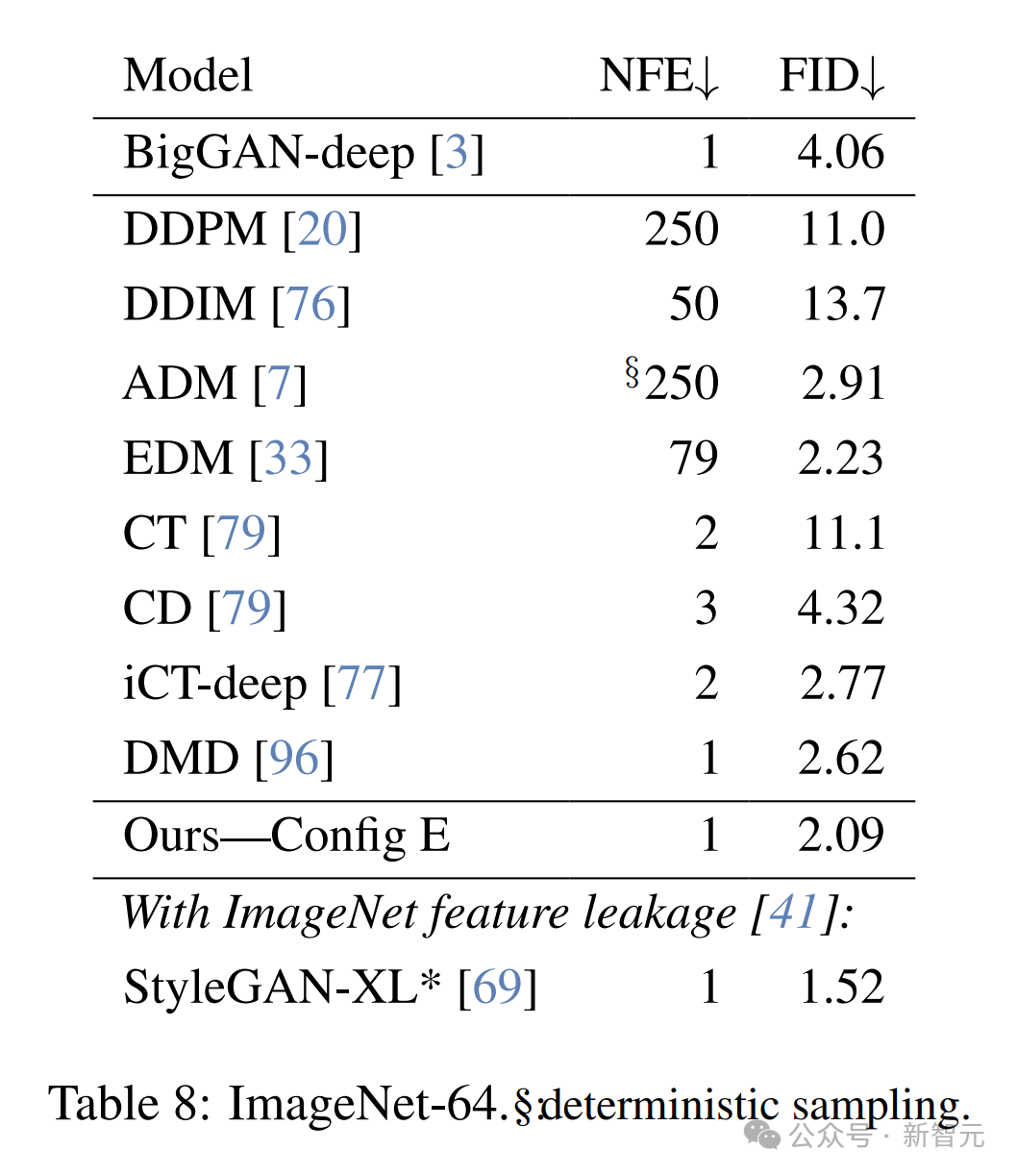
7. FID — ImageNet-64
研究人员在ImageNet-64数据集上评估了新模型,以测试其扩展能力。
他们在ImageNet-32模型的基础上增加了一个分辨率阶段,使生成器的参数量达到了104M。
这一模型的规模仅为基于ADM骨干的扩散模型的三分之一(ADM骨干约有300M参数)。
尽管新模型规模更小,且仅需一步即可生成样本,但在FID指标上仍然优于许多需要大量网络函数评估(NFE)的更大型扩散模型(如下表8所示)。
8. 召回率
研究人员又在每个数据集上评估了模型的召回率,以量化样本的多样性。总体而言,新模型达到了与扩散模型相似或略差的召回率,但优于现有的GAN模型。
对于CIFAR-10,新模型的召回率最高达到0.57;作为对比,StyleGAN-XL尽管FID更低,但其召回率更差,仅为0.47。
对于FFHQ,新模型在64×64分辨率下获得了0.53的召回率,在256×256分辨率下获得了0.49的召回率,而StyleGAN2在FFHQ-256上的召回率为0.43。
研究者的ImageNet-32模型达到了0.63的召回率,这与ADM相当。
另外,ImageNet-64模型达到了0.59的召回率。虽然这略低于许多扩散模型达到的约0.63的水平,但仍优于BigGAN-deep所达到的0.48的召回率。
作者介绍:
Yiwen Huang
Yiwen Huang(Nick Huang)目前是布朗大学计算机科学博士生。他曾于2023年获得了布朗大学硕士学位。
Aaron Gokaslan
Aaron Gokaslan是康奈尔大学的四年级博士候选人,导师是Volodymyr Kuleshov。此前,他在Facebook AI Research工作,由Dhruv Batra指导。
在此之前,他布朗大学完成了硕士和本科学业,师从James Tompkin。
Gokaslan的研究重点是识别、设计和构建高效、可扩展、可持续且经济的生成建模研究抽象和基础设施。我也在数据、法律和AI政策的交叉领域开展工作。
Volodymyr Kuleshov
Volodymyr Kuleshov目前是康奈尔大学计算机科学系助理教授。他曾在斯坦福大学获得博士学位,并获得了Arthur Samuel最佳论文奖。
他的研究主要关注机器学习及其在科学、健康和可持续性方面的应用。
James Tompkin
James Tompkin是布朗大学助理教授,专注于计算机视觉、计算机图形学和人机交互领域。
参考资料:
https://x.com/iScienceLuvr/status/1877624087046140059
https://huggingface.co/papers/2501.05441
https://x.com/multimodalart/status/1877724335474987040
https://x.com/SkyLi0n/status/1877824423455072523
本文地址:http://mip.sunnao.cn/archives/925
以上内容源自互联网,由运营助手整理汇总,其目的在于收集传播生活技巧,行业技能,本网站不对其真实性、可靠性承担任何法律责任。如发现本站文章存在版权问题,烦请提供版权疑问、侵权链接、联系方式等信息发邮件至candieraddenipc92@gmail.com,我们将及时处理。
相关推荐
-
微信悄悄加码图文
内容转载自:字母榜 微信将好友“塞进”了订阅号信息流里。 微信正在对公众号文章页面的“在看”功能进行小范围的更新测试。最新的灰度测试版本中,公众号文章底部的“推荐”取代了“在看”,…
-
国内各大AI产品功能横向对比及使用建议(2024年12月):文本生成、图片生成&图片处理、智能体篇更新汇总
内容转载自:产品经理崇生 在今年8月份,我曾撰写了如题的系列文章,分别就“文本生成”、“图片生成 & 图片处理”、“智能体”三个领域,给朋友们介绍了的国内各大AI产品的横向…
-
配置化理财商城,释放运营能效
内容转载自:烈焰成池 一、首先,对于配置化商城产品,想要实现怎样的效果? 搭建一个跨渠道管理,全页面要素可控可配的商城后台,将经过规则,人工运营相结合的方式完成产品内容信息与解构出…
-
《零售业创新提升工程的实施方案》启示录
内容转载自:零售商业财经 近年来,随着全球经济的深度融合和国内经济结构的持续优化,零售业作为连接生产与消费的关键环节,受到了国家政策层面的高度重视。 一系列政策的出台,不仅为零售业…
-
拼多多助力带来的赚钱机会!
内容转载自:十里村 关于拼多多的砍价助力,很多人一定觉得很烦! 甚至为此,拉黑了不少亲友。 但是不能忽视的一点,就是每天真实参与拼多多砍价的人实在太多了。 有以前嗤之以鼻的新客户,…
-
产品经理如何写出高质量年终报告
内容转载自:折柳先生 时间一晃而过,转眼就到年底收官的时候了。很多公司会在这个时候要求员工总结全年工作,提交年终报告。 面对年终总结,大致有两种截然不同的态度。一种态度认为年终报告…
-
20个商家,5点共同的小红书种草困惑
内容转载自:营销老王 我们这几年一直在服务大健康,母婴,护肤等赛道,以销售额为导向,帮中小品牌拿到不错结果,所以听完商家们顾虑,特别有共鸣。 我一直跟品牌强调,做种草投放,不要只以…
-
AGI加速到来,但无人真正关心
内容转载自:产业家 AGI 很快就会到来,但这不会是一个大事件。 AGI的实际定义变得更加谨慎,通常指的是“人类水平的智能”,而不是超级智能。许多AI专家认为,AGI不会带来科幻小…
-
「小模型」有更多机会点
内容转载自:王智远 为什么要研究语言模型。 原因主要有两点: 一,乔姆斯基认为,语言是思考的工具。要理解人类的心智,必须研究语言,语言和心智是密切相关,我们的主要观点是“压缩论”,…
-
一文看懂:数据指标体系的4大类型
内容转载自:接地气的陈老师 很多同学问:“有没有普遍的、一般的指标体系梳理方法?”网上常见的指标体系分享,大多是互联网的AARRR一类,现实中情况却很复杂。 普遍的方法当然有,就是…